


LPIRC 2019 Workshop Online Track
Update: Please visit https://docs.google.com/document/d/1Rxm_N7dGRyPXjyPIdRwdhZNRye52L56FozDnfYuCi0k/edit
This track has two categories:
- Interactive object detection. This category focuses on COCO detection models operating at 100 ms / image on a Pixel phone.
- Real-time image classification. This category focuses on Imagenet classification models operating at 30 ms / image on a Pixel phone.
A participant (or a team) can submit to and win prizes in either or both categories. The submissions will be a single model in TensorflowLite format (https://www.tensorflow.org/lite/)
A participant is encouraged to contribute to the TensorflowLite codebase (https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite) to support or expedite their models. Final scores will be computed using a stable build after submission closes. In case of significant latency regression in the final build, the latency measured at the time of submission may be considered at the discretion of the organizing committee.
1. Object Detection Challenge
1.1 Data
Both training and evaluation data are from the COCO object detection challenge. Competition will provide an online leaderboard showing model performance on the minival dataset (Image Ids found here). Final evaluation will use 2017 test-dev. Note that discrepancies are expected between these two metrics.
1.2 Evaluation
Submissions are evaluated based on task-performance (which is mAP for object detection and top-1 accuracy for image classification) under a targeted average latency. For object detection, the metric is COCO mAP and the targeted latency is 100ms per image.
The performance improvement will be measured relative to the empirical Pareto frontier, established by previous OVIC submissions as well as the Mobilenet family. Specifically, we estimate the Pareto frontier curve in the following parametric form:
a(t) = k log(t) + a0
where t is the average latency of the model, a(t) is the best task-performance at latency t, k and a0 are parameters.
Given a submission with performance A and latency T, the metric M of the submission is:
If T is within +/- 20% of the latency target:
M(A, T) = A - a(T)
If T is faster than 80% of the latency target, it’ll be treated as if the latency is 80% of the latency target.
If T is slower than 120% of the latency target, the submission is deemed invalid.
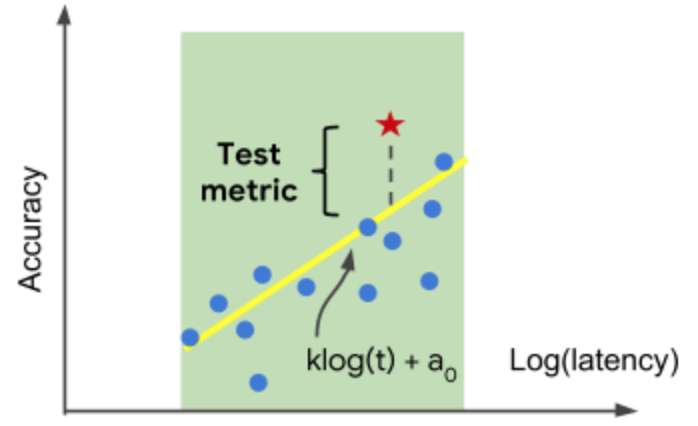
Figure above illustrates Pareto frontiers estimated from baseline models (shown as dots) and how the evaluation metric is computed for a submission (star) as the offset from the estimated frontier. Illustration only, no real data point used.
1.3. Benchmark environment
The submissions will be interpreted using the latest version of TfLite and benchmarked using a single thread with a batch-size of 1 on a single big core of phone in the Pixel series, most likely Pixel 2.
As the TfLite version may change during the competition period, the evaluation server will update frequently and re-measure the latency for all submissions. The best score (across all server builds) for each submission will be used towards the final scoring for that submission.
1.4. Input
The models must expect input tensors with dimensions [1 x input_height x input_width x 3], where the first dimension is batch size and the last dimension is channel count, and input_height and input_width are the integer height and width expected by the model, each must be between 1 and 1000. All images will be resized to these dimensions, and they should be picked judiciously to balance task-performance and latency. Inputs should contain RGB values between 0 and 255.
1.5. Output and model conversion
The output should contain four tensors:
- output locations of size [1 x 100 x 4] representing the coordinates of 100 detection boxes. Each box is represented by [start_y, start_x, end_y, end_x] where 0 <= start_x <= end_x <= 1, and 0 <= start_y <= end_y <= 1. The x’s correspond to the width dimension and the y’s to the height dimension.
- Output classes of size [1 x 100] representing the class indices of the 100 boxes. The index starts from 0.
- Output scores of size [1 x 100] representing the class probabilities of the 100 boxes.
- Number of detections (scalar) representing the number of detections. This must be 100.
The recommended way to produce these tensors is to use Tensorflow’s object detection API. Let config_path points to the TrainEvalPipelineConfig used to create and train the model, and checkpoint_path points to the checkpoint of the model. Participants can create a frozen tensorflow model in directory output_dir using the following command:
bazel-bin/tensorflow_models/object_detection/export_tflite_ssd_graph \
--pipeline_config_path="${config_path}" --output_directory="${output_dir}" \
--trained_checkpoint_prefix="${checkpoint_path}" \
--max_detections=100 \
--add_postprocessing_op=true \
--use_regular_nms=${use_regular_nms}
Where use_regular_nms is a binary flag that controls whether the regular non-max suppression is used, with the alternative being a faster non-max suppression implementation that is less accurate.
Participants can convert their Tensorflow model into a submission-ready model using the following command:
bazel-bin/tensorflow/lite/toco/toco \
--input_file="${local_frozen}" --output_file="${toco_file}" \
--input_format=TENSORFLOW_GRAPHDEF --output_format=TFLITE \
--inference_type=${inference_type} \
--inference_input_type=QUANTIZED_UINT8 \
--input_shapes="1,${input_height},${input_width},3" \
--input_arrays="${input_array}" \
--output_arrays=\
'TFLite_Detection_PostProcess',\
'TFLite_Detection_PostProcess:1',\
'TFLite_Detection_PostProcess:2',\
'TFLite_Detection_PostProcess:3' \
--change_concat_input_ranges=false --allow_custom_ops
--mean_values="${mean_value}" --std_values="${std_value}"
where local_frozen is the frozen graph definition;
inference_type is either FLOAT or QUANTIZED_UINT8;
input_array and output_array are the names of the input and output in the tensorflow graph; and mean_value and std_value are the mean and standard deviation of the input image.
Note that:
The input type is always QUANTIZED_UINT8, and specifically, RGB images with pixel values between 0 and 255. This requirement implies that for floating point models, a Dequantize op will be automatically inserted at the beginning of the graph to convert UINT8 inputs to floating-point by subtracting mean_value and dividing by std_value.
2. Image Classification Challenge
2.1. Data
Training data are from ImageNet classification dataset available at the ILSVRC 2012 website. The evaluation data are the holdout images from the 2018 competition.
2.2. Evaluation
The same relative metric in Section 1.2 is used for classification. The only differences are that the task-performance is top-1 classification accuracy, and the targeted latency is 30ms per image.
2.3 Benchmark environment and input
See Section 1.2 and 1.3 in object detection.
2.4. Output and model conversion
The output must be a [1 x 1001] tensor encoding probabilities of the classes, with the first value corresponding to the “background” class. The list of the full labels is here.
The participants can convert their Tensorflow model into a submission-ready model using the following command:
bazel-bin/tensorflow/lite/toco/toco -- \
--input_file="${local_frozen}" --output_file="${toco_file}" --input_format=TENSORFLOW_GRAPHDEF --output_format=TFLITE \ --inference_type="${inference_type}" \
--inference_input_type=QUANTIZED_UINT8 \ --input_shape="1,${input_height},${input_width},3" \
--input_array="${input_array}" \
--output_array="${output_array}" \
--mean_value="${mean_value}" --std_value="${std_value}"
See Section 1.5 of object detection for the definition of the arguments.
3. Resources:
Participants are encouraged to check out this tutorial (https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/quantize) for training quantized Mobilenet models.
Participants are also encouraged to check out Tensorflow’s ObjectDetectionAPI tutorial (https://github.com/tensorflow/models/blob/master/research/object_detection/README.md) for training detection models.
The following source code is provided to aid the development of the participants.
a. A Java validator to catch runtime errors of the model. Submissions failing the validator will not be scored.
b. A sample TFLite object detection model (see full instructions here).
c. A Java test to debug model performance.
d. An Android benchmarker app to time a submission on any Android phone.
Item d) allows the participants to measure latency of their submissions on their local phone. Note that latency obtained via d) may be different from the latency reported by the competition’s server due to language differences, device specs and evaluation settings, etc. In all cases the latency reported by the competition’s server will be used.
Disclaimers:
All submissions, along with the empirical Pareto frontier, will be re-computed after submission closes using the same codebase version. Regressions / improvements may happen as a result of versioning difference between the time of submission and the time of evaluation. In case of a significant regression the organizers may consider using the better measurement between the two.